
At a Big Data conference recently, IBM presented the following slide:

Interestingly, IBM also predicted that 1/3 of consumer data will be stored in the Cloud by 2016, and that 80% of new apps will be distributed or deployed via the Cloud. (IBM also once famously predicted that there would be a world market for 5 computers, which will perhaps one day be viewed as equally laughable as the Australian Prime Minister’s recent assertion that 25mbps Internet speeds are “more than enough”…)
The implications of Cloud Computing + Big Data are: exponentially more Internet traffic and therefore a need for faster, better, more reliable Internet services. A “Big Data Explosion” is certainly underway, and the implications for technology infrastructure are clear, as I attempted to illustrate with this graphic.

As discussed previously (in The Law (and Danger) of Averages), the problem with statistics, such as averages and medians, is that they are often misunderstood, and can be misleading. For example, if I have my left foot in the freezer (0 degrees) and my right hand in the fire (1000 degrees), and my body temperature is 40 degrees, then what temperature am I? Am I ok? My average temperature could be calculated as (0 + 40 + 1000)/3 = 347 degrees. My median would be (0, 40, 1000) i.e. 40 degrees. In this case the average indicates that we have a problem, the median does not.
So, in the case of so-called ‘median internet speeds’, what does this mean? Well, it depends on the methodology used to calculate the median. How was the measurement taken? When was the measurement taken? If it was taken at 5pm on a weekday, that would be different to if it was taken at 3am on a weekend, for example. Without such information, the measurements are pretty much useless for drawing any meaningful conclusions.
This is how ‘median ADSL speed’ is actually calculated on the much maligned “myBroadband” website:
“The column ADSL_SPEED_MEDIAN refers to the statistical median of the modelled peak download ADSL speed for each premises within a given DA. The specific speed measure that has been modelled is the line sync speed which refers to the cable distance between the relevant exchange or street cabinet and an individual premises. Other factors, as detailed in the Broadband Availability and Quality Report will also affect real world download speeds.”
So the fact that the actual signal gets slowed down by muddy, flooded pits and deteriorating, degraded copper is not reflected in these numbers. The fact that the signal is actually leaving the exchange via a ‘remote integrated multiplexor’ (sub-exchange), which slows the data down from 22mbps (ADSL2+) to 1.5-8mbps (ADSL1) is not reflected in these numbers. Talk about mis-representation of the data. It would appear that Australia’s entire broadband ‘strategy’ is being run along the lines suggested recently by Dogbert:

Dogbert on Dashboards
I was therefore very pleased to have stumbled across this crowdsourced survey of actual ADSL measurements, which formed the basis of a submission to the Senate Select Committee Hearing into the NBN (National Broadband Network – sometimes disparagingly referred to as the NBNNNNN i.e. “National Broadband Network – Not National Non-Network”). The team behind this excellent submission were more than willing to provide the raw data, which I turned into the following set of data visualisations:
When it comes to the Internet, everyone’s an ‘expert’ and everyone certainly has an opinion. However not all opinions turn out to be correct:

Hence the need for technologies such as Business Intelligence and Data Discovery tools, which aim to support “informed, fact-based decision making”. While that will not stop people from turning a blind-eye to the truth, particularly when it’s an “inconvenient” truth they would maybe rather deny, at least it gets the truth out there. (Hurrah for crowd-sourcing, social media and “Open Data”…)

 yield big improvements in unexpected areas. Be open-minded and willing to challenge perceptions. As Nolan Bushnell comments in his book “Finding the Next Steve Jobs”, Neutralize the Naysayers (“any idiot can say no”)
yield big improvements in unexpected areas. Be open-minded and willing to challenge perceptions. As Nolan Bushnell comments in his book “Finding the Next Steve Jobs”, Neutralize the Naysayers (“any idiot can say no”)







 For decades, the silo of choice was the spreadsheet. Today, it’s becoming the data discovery “workbook.” Yet it’s no longer enough to just have meaningful analytics: it’s also about speed.
For decades, the silo of choice was the spreadsheet. Today, it’s becoming the data discovery “workbook.” Yet it’s no longer enough to just have meaningful analytics: it’s also about speed. So what is Collaborative Business Intelligence? According to Howard Dresner, it is “a process where two or more people or organizations work together to develop a common understanding, which is shared and used to build consensus in support of organizational decision making.” Collaborative capabilities include sharing, annotating and co-authoring of business content.
So what is Collaborative Business Intelligence? According to Howard Dresner, it is “a process where two or more people or organizations work together to develop a common understanding, which is shared and used to build consensus in support of organizational decision making.” Collaborative capabilities include sharing, annotating and co-authoring of business content.
 As Howard Dresner commented, “Insight built collaboratively adds value faster and achieves faster consensus and better buy-in.” This in turn can help drive better organizational alignment to strategy and goals. It comes down to inspiring, motivating and empowering business users with a passion to help the organization drive better business outcomes for customers and shareholders.
As Howard Dresner commented, “Insight built collaboratively adds value faster and achieves faster consensus and better buy-in.” This in turn can help drive better organizational alignment to strategy and goals. It comes down to inspiring, motivating and empowering business users with a passion to help the organization drive better business outcomes for customers and shareholders. An era of social business solutions powering a more collaborating analytical process would certainly be music to my ears.
An era of social business solutions powering a more collaborating analytical process would certainly be music to my ears.
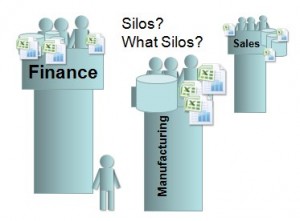 Yet historically, too many people, particularly those involved in Governance of BI systems, have essentially been ‘anti-collaboration’. Which has, ironically, made the situation worse by encouraging users to find ‘work-arounds’, resulting in, for example, the proliferation of spreadsheets. As Boris Evelson of Forrester Research recently commented to me in an email on this topic, “We increasingly hear from our clients that BI silos are now proliferating. Basically these platforms are now becoming the new spreadsheets”
Yet historically, too many people, particularly those involved in Governance of BI systems, have essentially been ‘anti-collaboration’. Which has, ironically, made the situation worse by encouraging users to find ‘work-arounds’, resulting in, for example, the proliferation of spreadsheets. As Boris Evelson of Forrester Research recently commented to me in an email on this topic, “We increasingly hear from our clients that BI silos are now proliferating. Basically these platforms are now becoming the new spreadsheets” The key to Collaborative BI is speed. Speed to a decision. Having better, more informed, fact-based conversations with the right people. As the Irish playwright G. Bernard Shaw famously commented:
The key to Collaborative BI is speed. Speed to a decision. Having better, more informed, fact-based conversations with the right people. As the Irish playwright G. Bernard Shaw famously commented:
 In this context, “BI Governance” includes things like BI lineage, impact analysis, facilitating collaboration and content reuse, reducing content duplication. In the BI industry in general, we’ve seen what Wayne Eckerson recently referred to as a “pendulum swing” – away from (over) governed BI to un-governed BI. The pendulum is now swinging back, because business users are now starting to ask questions like:
In this context, “BI Governance” includes things like BI lineage, impact analysis, facilitating collaboration and content reuse, reducing content duplication. In the BI industry in general, we’ve seen what Wayne Eckerson recently referred to as a “pendulum swing” – away from (over) governed BI to un-governed BI. The pendulum is now swinging back, because business users are now starting to ask questions like: I’m reminded of something I noticed on a Deep Purple record “Made in Japan”, recorded back in 1971. Ian Gillan, the vocalist, can be overheard asking the sound engineer: “Yeah everything up here please. A bit more monitor if you’ve got it.” To which Ritchie Blackmore, the guitarist, adds: “Can I have everything louder than everything else?”
I’m reminded of something I noticed on a Deep Purple record “Made in Japan”, recorded back in 1971. Ian Gillan, the vocalist, can be overheard asking the sound engineer: “Yeah everything up here please. A bit more monitor if you’ve got it.” To which Ritchie Blackmore, the guitarist, adds: “Can I have everything louder than everything else?”






